Instrumente
Die folgenden Parameter sind Teil der Datenstruktur surveyPart. Sie bilden zusammen die Voraussetzung, eine Erhebung durchzuführen. Es handelt sich also um die Beschreibung des Testmaterials im engeren Sinne.
Begriffe und Struktur
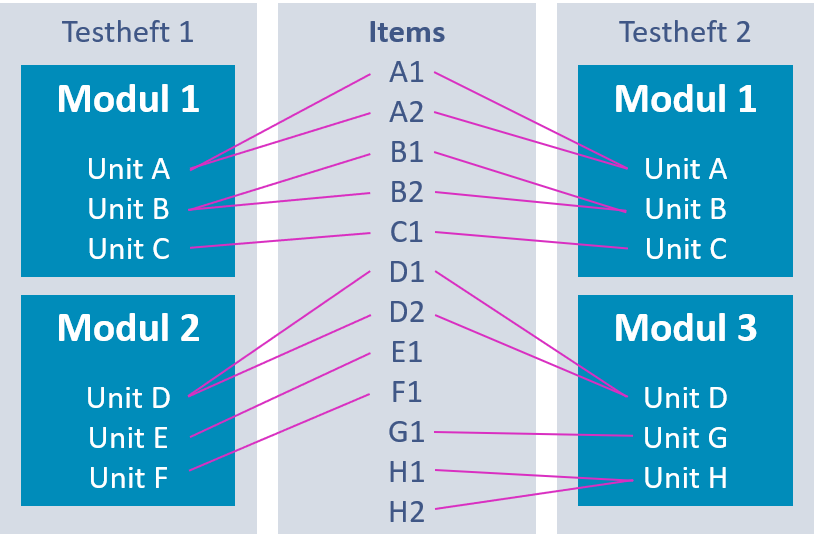
Instrument, Testheft
Eine Aufgabenfolge, die die Testperson in einer Testsitzung abarbeiten soll, nennen wir “Testheft” oder “Instrument” (synonym). Der Zeitrahmen bei Lernstandserhebungen liegt zwischen 40 bis 120 Minuten. Sollte sich der Test auf verschiedene Tage verteilen, wird man nicht das angefangene Testheft fortsetzen, sondern die Aufgaben auf mehrere Testhefte verteilen.
Modul
Die Aufgaben werden nicht frei im Testheft platziert, sondern vorher in Module gesetzt. Anschließend wird das Modul in verschiedene Testhefte eingefügt. Die Aufteilung eines Testheftes in Module folgt vor allem praktischen Erwägungen. Die Kommunikation ist einfacher, wenn man vom “Leseblock” und “Ergänzungsblock” redet.
Units, Items
Dieselbe Unit kann in verschiedene Blöcke eingefügt werden – man muss dann halt nur darauf achten, dass die Blöcke entsprechend eingesetzt werden (“Unverträglichkeit”). Es gibt aber auch Units, die bewusst mehrfach im selben Testheft eingesetzt werden, z. B. Fragen zur Motivation.
In einer Unit sind dann Variablen zu finden, die nach Interaktionen die Antwortdaten generieren. Die Antwortdaten werden zu einem späteren Zeitpunkt zu Itemwerten transformiert. Ein Item ist eine Teilaufgabe und auf dieser Ebene wird die Schätzung der Personenfähigkeiten vorgenommen.
bookletModules
Der oben dargestellten Struktur folgend setzt man zuerst die Units in Module. Dieser Arbeitsschritt wird durch die Datenstruktur bookletModules nachgebildet:
id, name, description, lang
Im Datenmanagement müssen ein verlässlicher Bezug zu einem Abschnitt id sowie Erläuterungen über die Datenfelder name und description hinterlegt sein. In Auswahllisten oder Protokollen kann dann das Modul gut identifiziert werden.
name und description haben keine separate Sprachmarkierung, denn das Modul wird zu genau einer Sprache entwickelt. Daher ist in einem Feld lang die Sprache anzugeben, die dann für alle Einträge des Moduls gilt.
units
Es sind alle Units aufgeführt, die Teil des Moduls sind. Jede Unit hat folgende Felder:
idkennzeichnet die Unit, so wie sie unabhängig vom Einsatz in Testheften entwickelt wurdealiasbezieht sich auf eine spezifische Unit in einem spezifischen Testheft an einer spezifischen Stelle. Da Units in Testheften mehrfach auftauchen können, ist eine solche Angabe nötig. Deraliaseiner Unit wird verwendet, um die Antworten zu speichern – NICHT dieidder Unit!name,descriptionbeschreiben die Unit für die UIorderkennzeichnet die Position innerhalb des Moduls.dependencies: Liste aller Dateien, die im Zusammenhang mit der Unit vorliegen müssen. Neben der ID, die auch einen Pfad enthalten kann, ist eintypeanzugeben. Die möglichen AusprägungenUNIT_XML,CODING_SCHEME,METADATA,UI_DEFINITION,PLAYER,PLAYER_DEPENDENCY,WIDGETermöglichen eine korrekte Zuordnung zu Funktionen.
instruments
Module werden in Testhefte platziert (s. obige Struktur).
id, name, metadata
Im Datenmanagement müssen ein verlässlicher Bezug zu einem Abschnitt id sowie Erläuterungen über name hinterlegt sein. Das Instrument selbst ist nicht auf die Sprache festgelegt, d. h. der Name muss wieder mit einer Sprachmarkierung versehen sein.
Das IQB nutzt seit einigen Jahren konsequent ein eigenes Metadatensystem, das auf internationalen Standards beruht. Kern sind Vokabulare, in denen Wertelisten für spezifische Merkmale veröffentlicht sind. Verschiedene Metadaten werden dann Objekten über sog. Metadatenprofile zugewiesen. Es handelt sich um ein sehr flexibles und universelles Verfahren, digitalen Objekten Zusatzinformationen zuzuweisen, ohne jedes Mal die Spezifikation ändern zu müssen.
Weitere Informationen und Literatur finden Sie hier. Die Metadatenprofile, die im SCP-Index verwendet werden, finden Sie hier
{
"metadata": {
"profileId": "https://raw.githubusercontent.com/iqb-vocabs/p44/master/index.json",
"entries": [
{
"id": "e1",
"label": [
{
"lang": "de",
"value": "Art der Erhebung"
}
],
"value": [
{
"id": "https://w3id.org/iqb/v85/dt/1"
}
],
"valueAsText": [
{
"lang": "de",
"value": "Kompetenz- und Leistungsdaten"
}
]
},
{
"id": "kim_type_school",
"label": [
{
"lang": "de",
"value": "Schulform"
}
],
"value": [
{
"id": "https://w3id.org/kim/schularten/s02"
}
],
"valueAsText": [
{
"lang": "de",
"value": "Grundschule"
}
]
}
]
}
}testcenterBooklet
Diese Liste enthält alle Sprachvarianten für genau ein Booklet. Jeder Eintrag hat folgende Eigenschaften:
lang: Definition der Sprache dieser VariantedefinitionId: ID/Pfad zur XML-Datei, die das Booklet beschreibt und genau so in das Testcenter hochgeladen werden muss.modules: Aufzählung aller Module, die in diesem Booklet verwendet wurden. DiemoduleIdverweist in die ListebookletModulesdes Abschnittes. Es gibt die Möglichkeit, eine Reihenfolgeorderder Module festzulegen.
administrationMode
Es gibt – z. B. bei StarS – Abweichungen vom normalen Szenario “Schüler*in löst Aufgaben”. Das Booklet kann verschiedene Modi der Durchführung haben:
TEST_BY_TEST_TAKER: Der Test/die Befragung wird von derselben Person durchgeführt, deren Fähigkeiten ermittelt werden sollen (Standard),TEST_BY_PROCTOR: Der Test wird durch die Lehrkraft/Aufsicht durchgeführt (Dialog/Beobachtung), um die Fähigkeiten einer anderen Person zu erheben,STIMULUS_FOR_TEST_TAKER: Die Testperson geht durch das Booklet, ohne Anworten zu hinterlassen. Sie wird dabei von einer Lehrkraft/Aufsicht begleitet, die die eigentliche Erfassung vornimmt. Im Testcenter wird als DurchführungsmodusRUN_DEMOgewählt, d. h. das Booklet dient mehreren Testpersonen als Stimulus und hinterlässt keine Antwort-Daten.
handOutsForTestTaker
Es kann sein, dass für dieses Booklet zusätzliches Material an die Testperson(en) gegeben wird. Entweder dient dieses Material als zusätzlicher Stimulus, oder die Testperson soll eine Handlung damit/darauf ausführen. Beispielsweise soll ein Wort aufgeschrieben oder eine Linie gezogen werden. Die Handlungen der Testperson werden aktuell nicht direkt in die Testergebnisse einbezogen (Scan), sondern es müsste parallel über ein Instrument eine Beobachtung stattfinden, die die Handlung kodiert. Daher kann ein Handout nicht getrennt von einem Instrument definiert werden.
Die Liste enthält Einträge mit folgenden Eigenschaften:
orderkann die Anzeigereihenfolge festlegen.modebeschreibt die Art des Einsatzes:PRINT_SHOW: Ausdruck nur zum Zeigen. Bei Einzeltestungen reicht dann ein Ausdruck pro Testgruppe.PRINT_WRITE_DRAW: Ausdruck, auf dem die Testperson schreibt oder zeichnet.ON_SCREEN: Anzeige auf einem Bildschirm (Tablet, Laptop).
filesetzt eine Referenz zu der Datei, die als Quelle für das Handout dient. Da es mehrere sprachspezifische Varianten geben kann, ist hier ein Array mit den Wertenid(ID/Pfad),langfür die Sprachangabe undlabelfür die UI anzugeben. Auch eine Beschreibungdescriptionkann hinzugefügt werden.